Stack de métrologie à Picasoft
Principes généraux d'une stack de métrologie
Une solution de métrologie se décompose généralement en différents composants, chacun ayant un rôle bien spécifique.

D’un côté les différentes applications et serveurs, qui produisent des métriques. De l’autre la solution de métrologie.
Composants
Collecte
Le premier composant se charge de collecter les métriques. Il existe 2 modèles pour cela : le push ou le pull.
Le modèle push implique que ce sont les serveurs et applicatifs qui vont envoyer les métriques au composant de collecte. Cette pratique a les avantages suivants :
- les sondes décident de quand elles envoient des métriques, par exemple uniquement lorsque les valeurs sont mises à jour, ou après l’exécution d’un évènement particulier (ex. tâche cron)
- les services et serveurs sont autonomes : lorsque l’on déploie un nouveau service il envoie automatiquement ses métriques, il n’y a pas de configuration à modifier côté outil de collecte
Cependant le modèle push a les inconvénients suivants :
- il faut autoriser l’accès à l’outil de collecte depuis la totalité de l’infrastructure. Il faut s’attendre à une configuration firewall ou d’authentification complexe côté de l’outil de collecte
- si l’outil de collecte est indisponible, la totalité des sondes auront une erreur. Si cette erreur n’est pas bien gérée (ce qui est probable, la sonde n’était pas la fonction première de l’application on peut s’attendre à une moins bonne fiabilité au développement) cela peut avoir des effets de bords directs sur l’application.
Pour ces raisons, le modèle pull est souvent préféré. Dans ce modèle, c’est l’outil de collecte qui va se charger de contacter directement les sondes pour récupérer les métriques. Il suffit de donner l’accès, sur tout les services, depuis un seul point de l’infrastructure (l’outil de collecte), et en cas de défaillance il ne se passe rien du côté des sondes (et donc des applicatifs).
Traitement
Le traitement est, comme son nom l’indique, la phase de traitement des métriques collectées. Elle est réalisée directement après la collecte et permet d’effectuer des opérations avant le stockage des mesures. La plupart du temps cela consiste en l’ajout de méta-données (par exemple la date, la machine d’origine, etc.) sur les métriques.
En réalité, cette étape est souvent intégrée dans l’outil de collecte, pour ne former d’un seul composant qui va collecter et traiter les données.
Stockage
Le stockage de timeseries est assez particulier : ce sont des données très petites (quelques octets/kilo-octets et données et méta-données), mais en très grand nombre (plusieurs centaines, milliers, ou plus, par minute) et fortement liées (les métriques sont une succession de points). Pour cela les bases de données classiques ne font pas l’affaire, et des bases de données spécialisées existent : les TSDB, pour Time Series DataBase.
Visualisation
Enfin, le dernier composant permet de visualiser les métriques ainsi collectées et stockées. La plupart du temps cet outil se connecte à la TSDB pour faire des requêtes, mais il arrive parfois que le fonctionnement soit que l’outil de “Traitement” serve aussi à s’interfacer avec la TSDB en lecture, et donc que l’outil de visualisation se connecte avec celui de traitement.
Exemple de stack "Prometheus"
Selon les outils choisis pour la solution de métrologie, il peut donc y avoir quelques variations (modèles push ou pull, collecte et traitement regroupés, etc.). Voici un exemple de stack basée autour du logiciel Prometheus.

Prometheus est un logiciel de collecte et de traitement des métriques très utilisé, qui fonctionne sur le modèle du pull. Pour cela on déploie des exporters au niveau des applications, des serveurs, etc. (les composants que l’on souhaite mesurer), qui expose des métriques via une simple page textuelle accessible en HTTP. Le serveur Prometheus est configuré pour aller collecter (on parle de scrapping) les exporters régulièrement.
Les métriques sont ensuite stockées par Prometheus au sein d’une TSDB. Il en existe de nombreuses compatibles avec Prometheus, l’une des plus connues étant |InfluxDB.
Enfin la visualisation se fait quasi-exclusivement avec Grafana, qui est la solution qui domine largement dans ce domaine. Cet outil s’intègre avec des nombreuses TSDB ainsi qu’avec Prometheus. Généralement, Grafana fait les requêtes auprès de Prometheus (à l’aide de son langage PromQL) qui s’interface avec la TSDB.
Stack de Picasoft
Picasoft a choisi de centrer sa stack de métrologie autour de Victoria Metrics, qui est une Time series database assez récente. L’intérêt premier de cette TSDB est qu’elle propose nativement une compatibilité avec d’autres outils de métrologie : elle intègre un outil qui peut réaliser une collecte compatible avec Prometheus et d’autres TSDB (comme InfluxDB), et propose un langage de requête lui aussi compatible avec Prometheus.
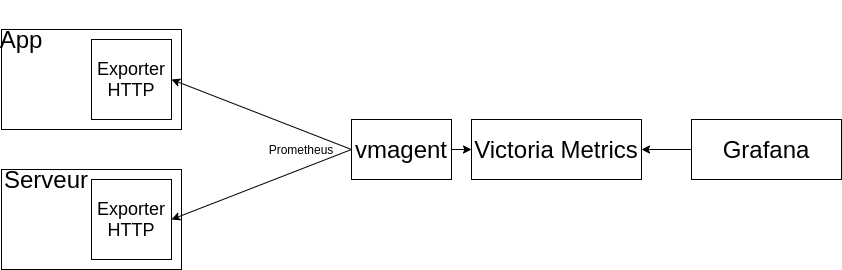
L’ingestion de métriques se fait uniquement avec l’outil vmagent, qui propose une compatibilité avec plusieurs protocoles. Dans le cas de Picasoft nous l’utilisons pour collecter des métriques auprès d’exporters Prometheus pour les machines ou les services.
vmagent communique ensuite les métriques à Victoria Metrics qui va les stocker et les rendre disponible en consultation, ici aussi en proposant une compatibilité avec plusieurs protocoles. Dans le cas de Picasoft on utilise PromQL (de Prometheus) pour faire des requêtes de Grafana dans la base Victoria Metrics.